In the previous blog we explained what Kafka Connect is, what we can do with it, and what are some of the most important components that we can use to establish a reliable and fault-tolerant big data pipeline.
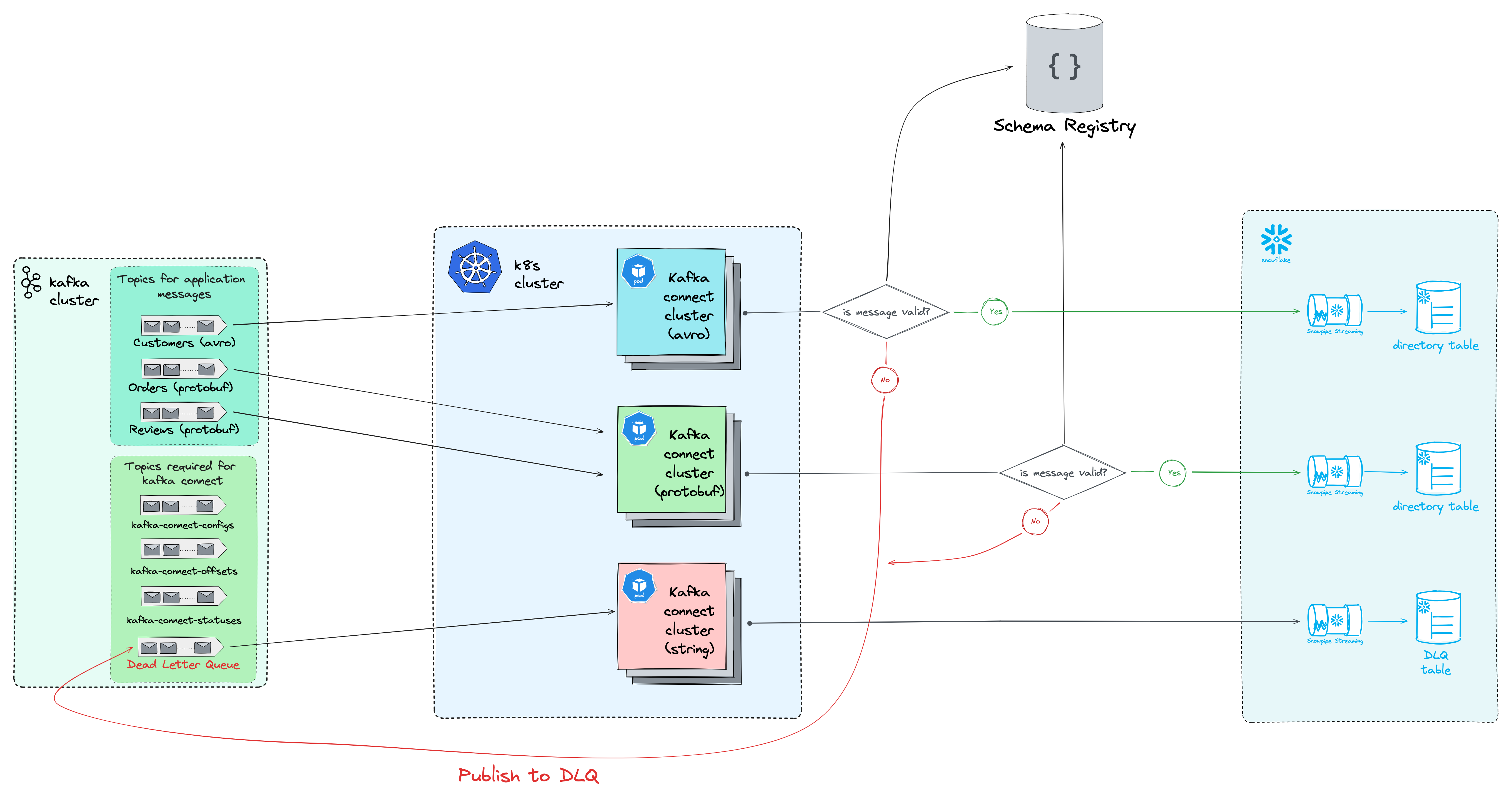
In this blog, we will deploy a small-scale but production-ready Kafka Connect cluster where we will take Avro and Protobuf messages from different topics and store them in Snowflake tables. We will use Schema Registry to validate our Avro and Protobuf schemas.
In theory, it seems like a straightforward process but in practice, it can get a bit complex especially if you are setting up Kafka Connect for the first time. So many properties can be easily overlooked, but precisely those properties can save you from losing your precious Kafka messages.
We will go over the whole process and show you how we can set up a production-ready pipeline from scratch.
Environment setup
-
Kubernetes cluster*
-
Kafka cluster
-
Schema registry
-
Snowflake account
*Kubernetes cluster is not required, but if you plan to set up Kafka Connect somewhere else (like EC2, VMs), you must make some adjustments.
All the above services (besides Snowflake) can be deployed locally or you can use managed services.
To make this blog less complex since the main focus is on Kafka Connect, (for our example), we will use Confluent Platform for the Kafka cluster and schema registry.
We understand that not everybody can use Confluent Platform for commercial projects, and you do not have to. The process is not tied to Confluent, which can be achieved without using any Confluent products; instead, it can be done using open-source software.For reference, our company is not using anything related to Confluent, not even the schema registry or converters.If you want to use Confluent Platform to follow along, there is a 30 day free trial that is more than enough to replicate everything from this blog. The same 30 day trial exists in Snowflake too.
To confirm that it also works without the Confluent Platform we also deployed Kafka using Koperator on our Kubernetes cluster, and the setup was the same. For the schema registry, you can try out Karapace.
This is just an intro, you can check out the full blog (for free) at: